A search engine is an online tool that locates all the potentially relevant results on the web, removes all the spam, and ranks them based on hundreds of factors, like keywords, links, locations, and freshness.
Keep reading to know more about search engine examples, working, and importance.

Table of Contents
Search Engine Example
Imagine that you are a librarian and when people come into your library, it’s your job to help them to find the book they are looking for. Imagine that your library is a giant one that consists of over 100 million books with no formal organized filing systems. How you will manage it?.
First, you need a system to organize all books, your system should know that what’s over on 200 trillion pages. Additionally, you need to answer up to 40000 customer inquiries per second and spit out the most relevant answer to each question.
Search engines like google, yahoo and bing are librarians and the giant library is the internet. They have a system to collect information about every page on the internet to provide their customers with the most relevant search results.
Primary Function of Search Engine
Primary functions of search engine are as follows:
- Crawling: Search the Internet for content, looking over the content for each URL search engine find.
- Indexing: Store and compile the content found during the crawling process. Once a page is in the index, it’s in the running to be displayed as a result of relevant queries.
- Ranking: Provide the pieces of relevant content that will best answer a searcher’s query.
Crawling
First, to locate relevant content on over a hundred trillion web pages, a search engine employs a spider also refer to as a bot or crawler, which is a program that finds relevant information and builds a list of words found on each site, this process known as web crawling. Web crawling is where it all begins and for that matter, it never ends. Spiders quickly and frequently scan sites and compile a list of everything presented on the site including content, page titles, headers, keywords, images, link pages and much much more.
Indexing
The second function of a search engine is indexing. In this process, the bot processes all the information it gathers and compiles a massive index of the words and respective location.
Ranking
The last function is to provide users with a list of relevant results based on their search. When a user enters a query, the search engine scans the index to locate the most relevant sites. It then returns the results it believes are most relevant to the users. We refer to this as a ranking.
How search engine’ Site Crawlers Index Your Site?
When the crawler finds your site, it will start to read posts and pages on your site. The crawler will read the content of those posts and pages and will add an HTML version of them to the gigantic database, called the index. This index is updated every time the crawler visits your website and finds a new and revised version of it. Depending on how important the search engine deems your site and the number of changes you make to your website, the crawler comes around more or less often. The crawability stands for the possibilities the search engine has to crawl your website. These possibilities can be restricted in a number of ways by blocking the crawler from your website. If your website or a page on your website is blocked, you are saying to search engine crawler: “Do not come here”. Your site or the respective page won’t turn up in the search results in most cases.
There are few things that can prevent search engine like Google, from crawling and indexing your website.
The first method is the robots.txt file. It’s a text file. Before a search engine spider crawls any page, it has not encountered before, it will open the rotbots.txt file for that site. The robots.txt file will tell the search engine which URLs on that site it’s allowed to visit. Using a rotbots.txt file, you can tell a spider where it cannot go on your site.
In the second method, you can use an HTTP header to prevent a search engine from crawling and indexing a page. This HTTP header contains a status code. If this status code says that page doesn’t exist, the search engine will not crawl it. There are several codes with different meanings. If the status code is, for example, 200, the page exists and google can crawl your page. If the status code is 307, the page has been redirected to another URL and google would not crawl the current URL.
In the third method, you can use robots meta tags to block google from indexing that page. These are short pieces of code that tell Google what it can do and what it cant do. There are several robots meta text values. To prevent google from adding that page to its index, you can use the no index value. Google will crawl that page but won’t add it to the index. The opposite value of no index is the index that can be used to tell Google it can add the page to its index. Another useful robot meta tag is the nofollow value. The nofollow value tells the crawler to not follow any links on this specific page at all. The opposite of nofollow value is follow value. You don’t have to manually set the index or the following values as they are the default for any page that the crawler will encounter.
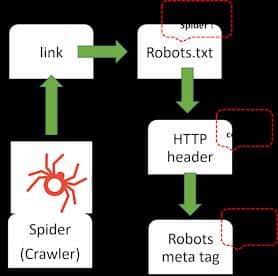
Summary of crawling and indexing steps
Crawler finds a link to a page on your site. First, it will check the robots.txt to verify whether it’s allowed on that page. If the crawler is allowed by the robots.txt to crawl your site, it will check the HTTP header of the page for a status code. If the status code is 200, everything is OK and the crawler will crawl the entire engine. Lastly, It will check the robots meta tag. If the robots meta tag allows for indexing, it will add the page to Google’s search index and the page can be found when you search in Google.
How to check if your site is correctly indexed by Google
One way to check your indexed pages is “site:yourdomain.com”, an advanced search operator. Open Google search bar and type “site:yourdomain.com” into the search bar. This will return the results Google has in its index for the site specified:
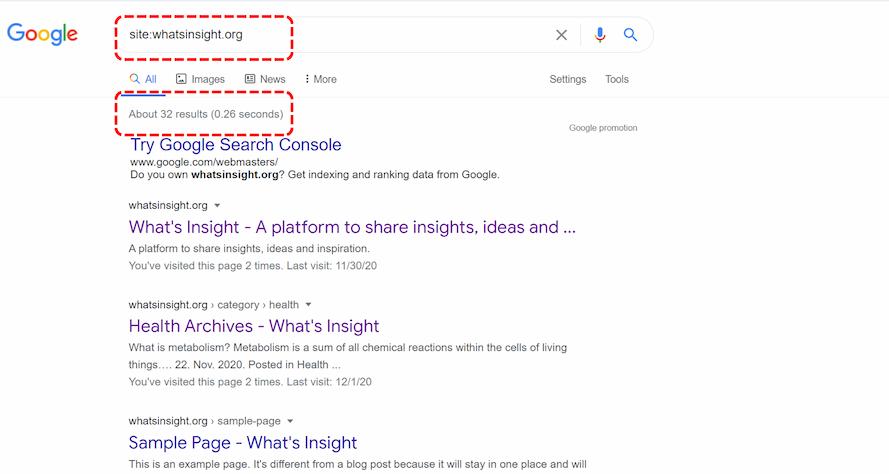
The number of results Google displays (see “About 32 results (0.26 seconds)” above) isn’t exact, but it does give you a solid idea of which pages are indexed on your site and how they are currently showing up in search results.
For more accurate results, monitor and use the Index Coverage report in Google Search Console. Search console is a free tool from Google, that helps website owners, search engine optimization professionals, and developers understand how they are performing on Google search and what they can do to improve their appearance and search to bring more relevant traffic to their websites. Search console is not a requirement to appear in the organic search result, but it can definitely help you monitor and optimize how Google crawls, indexes, and serves your website to users. Some basic functions of search console are:
- Learn how Google crawls, indexes, and discovers
- Fix errors
- Submit updated content
- Monitor search performance
Search Engine Evaluator
Search engine evaluators are people who keep a check on the algorithms that search engine runs.
Their task is to provide feedback and ratings about what search engine shows after search.
This feedbacks ensure that search results are relevant, comprehensive, accurate, spam-free, and timely.
Search Engine-Summary
When you do a web search in the search engine, you are actually searching the search engine’s index of the web. The search engine does this by software programs called spiders. Spiders start by fetching a few web pages then they follow the links on those pages and fetch the pages they point to and follow all the links on those pages and fetch the pages they link to and so on until it has indexed a pretty big chunk of the web, many billions of pages stored cross thousand of machines. In the index, there are hundreds of thousands of possible results.
Frequently Asked Questions (FAQs)
Search engine decides the ranking of pages by asking questions like how many times does this page contains the keyword? do the keywords appear in the title or URL? does the page includes synonyms for those words? is this page from a quality website? how many outside links point to it?. Finally, the search engine combines all these factors together to produce each page’s overall score and send you back your search results. For more details check cloud computing, machine learning and artificial intelligence topics.
Learn how Google crawls, indexes, and discovers
Fix errors
Submit updated content
Monitor search performance

Please send any feedback to [email protected]
- BCl3 Lewis Structure in four simple steps - November 1, 2023
- PH3 Lewis Structure in four simple steps - October 8, 2023
- PF3 Lewis structure in four simple steps - September 24, 2023


